Usage of fuzzy hashes
Introduction
Fuzzy hashes are used to search for similar messages – i.e. you can find messages with the same or a slightly modified text using this method. This technology fits well for blocking spam that is simultaneously sent to many users. Since the hash function is unidirectional, it is impossible to restore the original text using a hash only. And this allows you to send requests to third-party hash storages without risk of disclosure.
Furthermore, fuzzy hashes are used not merely for textual data but also for images and other attachments types in email messages. However, in this case, rspamd looks for the exact matches to find similar objects.
This article is intended for mail system administrators who wish to create and maintain their own hash storage.
Step 1: Hash sources selection
It is important to choose the sources of spam samples to learn on. The basic principle is to use spam messages that are received by a lot of users. There are two main approaches to this task:
- working with users complaints;
- creating spam traps (honeypot).
Working with users complaints
It is possible to study users’ complaints for improving hash storages. Unfortunately, users sometimes complain about legitimate mailings they’ve subscribed on to by themselves: for example, stores newsletters, notifications from tickets booking and even personal emails which they do not like for some reasons. Many users simply do not see the difference between “Delete” and “Mark as Spam” buttons. Perhaps, a good idea would be to prompt a user for additional information about the complaint, for example, why he or she decided that it is a spam email, as well as to draw the user’s attention to the fact that user is able to unsubscribe from receiving mailings instead of marking them as spam.
Another way to solve this problem is manual processing of user spam complaints. A combination of these methods might also work: assign greater weight to the manually processed emails, and a smaller one for all other complaints.
There are also two features in rspamd that allow to filter out some false positives:
- Hash weight.
- Learning filters.
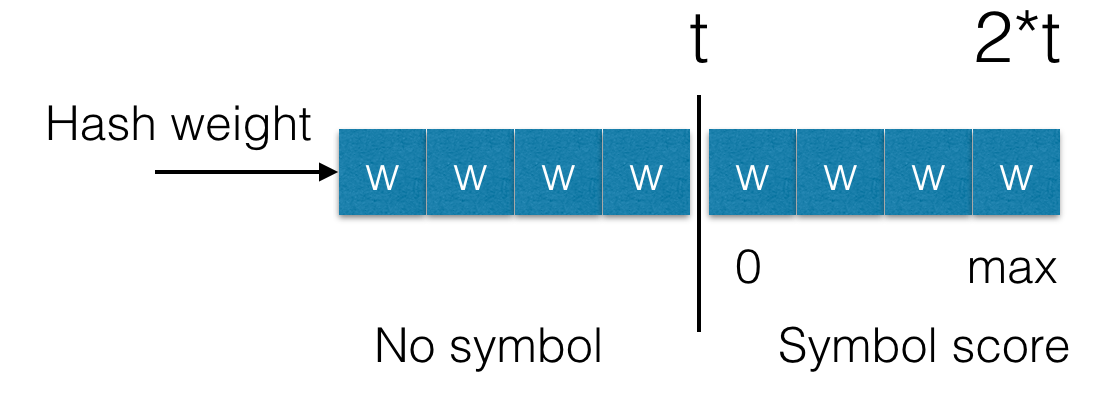
The first method is pretty simple: let’s assign some weight to each complaint, and then we add this weight to the stored hash value for the each subsequent learning step. During querying a storage we will not consider hashes with weights that are less than a defined threshold.
For instance, if the weight of a complaint is w=1 and the threshold is t=20, then we ignore this hash unless receiving at least 20 user complaints.
In addition, rspamd does not assign the maximum score finding a threshold value - scores gradually increases from zero to a maximum (up to metric value) when the weight of hash grows up to the threshold value multiplied by two (t .. 2 * t).
The second method, namely learning filters, allows you to write certain conditions that can skip learning or change a value of hash for instance, for emails from a specific domain (for example, facebook.com). Such filters are written in Lua language. The possibilities of the filters are quite extensive, however, they require manual writing and configuring.
Configuring spam traps
This method requires a mailbox that doesn’t receive legitimate emails but spam emails instead. The main idea is to expose the address to spammers’ databases, but do not show it to legitimate users. For example, by putting emails in a hidden iframe element on a fairly popular website. This element is not visible to users due to hidden property or zero size but it is visible for spam bots. Recently, this method has become not very effective, as spammers have learnt how to abstain from such traps.
Another possible way to create a trap is to find domains that were popular in the past but that are not functional at the moment (addresses from these domains could be found in many spam databases). In this case, learning filters are required as legitimate emails, for instance, social networking or distribution services, will likely be blacklisted.
In general, setting own traps is reasonable merely for large mail systems, as it might be expensive both in terms of maintenance and as direct expenses, e.g. for purchasing domains.
Step 2: Configuring storage
In this chapter, we describe the basic fuzzy storage settings and how to optimize its performance.
Important note: fuzzy storage works with hashes and not with email messages. Hence, in order to convert a email into the corresponging set of hashes you need to use a scanner (for checking) or a controller process:
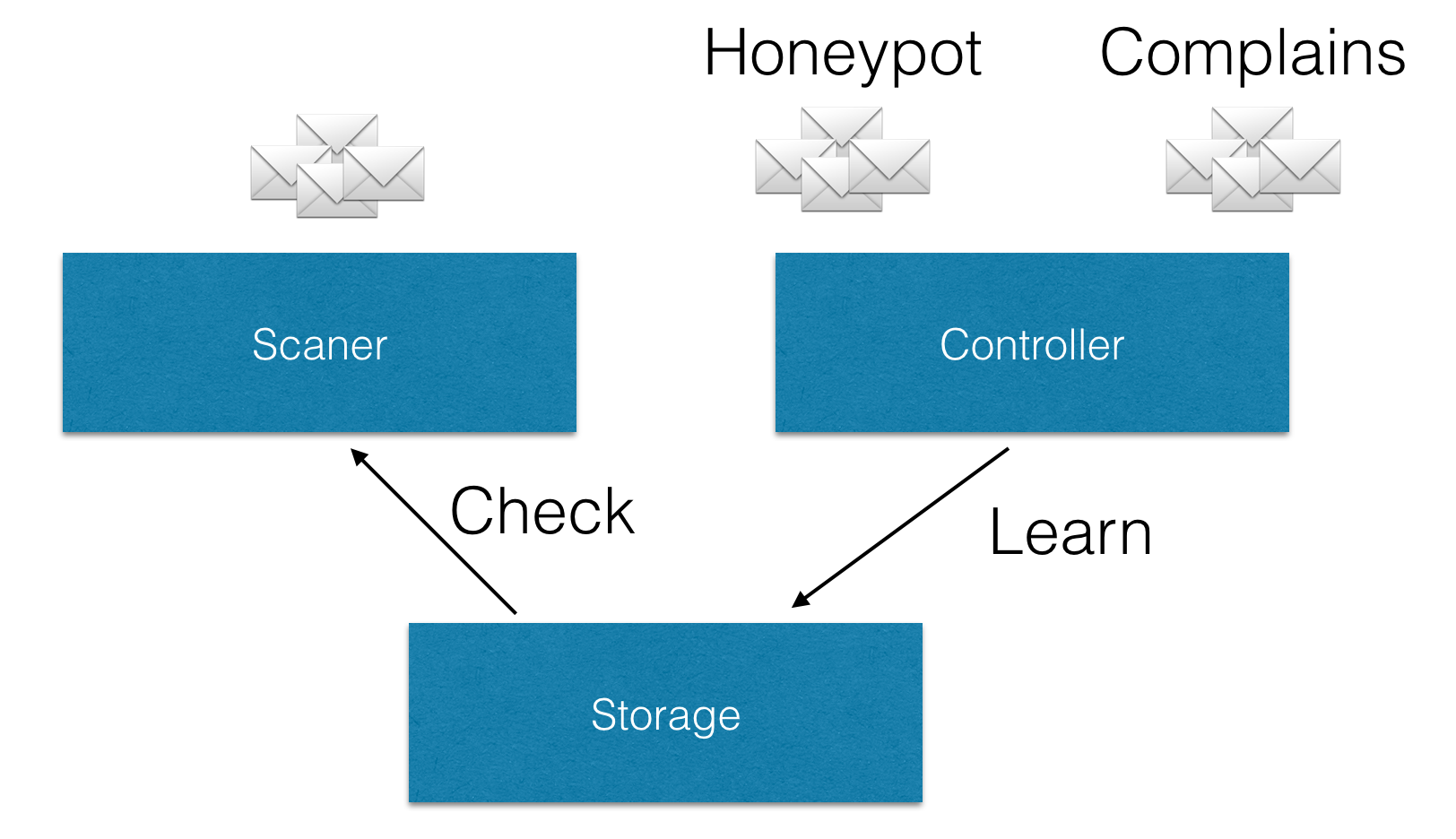
Fuzzy storage functions:
- Data storage
- Transport Protocol Encryption
- Hashes expiration
- Access control (read and write)
- Replication (since v. 1.3)
Storage architecture
The database engine, namely sqlite3, imposes some restrictions on the storage architecture.
Firstly, sqlite cannot deal well with concurrent write requests: in this case, the database performance is degraded significantly. Secondly, it is quite difficult to provide replication and scale the database as it requires third-party tools.
Therefore, rspamd hash storage always writes to the database strictly from one process. To reach this goal, one of the processes maintains the updates queue whilst all other processes simply forward write requests from clients to the selected process. The updates queue is written to the disk once per minute (by default). Such an architecture is optimized for the load profile with prevalence of read requests.
Hashes expiration
Another major function of the fuzzy storage is removing of the obsolete hashes. Since the duration of spam mailings is always limited, there is no reason to store all hashes permanently. It is better to compare the quantity of hashes learned over some time, with the available RAM amount. For example, 400 thousands hashes occupy about 100 Mb and 1.5 million hashes occupy 0.5 Gb.
It is not recommended to increase storage size more than the available RAM size due to a significant performance degradation. Furthermore, it makes no sense to store the hashes for longer than about three months. Therefore, if you have a small amount of hashes suitable for learning, it is better to set expiration time to 90 days. Otherwise, when RAM size is less than the learn flow over this time, it is better to set a shorter period of expiration.
Sample configuration
The rspamd process that is responsible for fuzzy hashes storing is called fuzzy_storage. To turn on and configure this process you may use the local file of rspamd configuration: /etc/rspamd/rspamd.conf.local:
worker "fuzzy" {
# Socket to listen on (UDP and TCP from rspamd 1.3)
bind_socket = "*:11335";
# Number of processes to serve this storage (useful for read scaling)
count = 4;
# Backend ("sqlite" or "redis" - default "sqlite")
backend = "sqlite";
# sqlite: Where data file is stored (must be owned by rspamd user)
database = "${DBDIR}/fuzzy.db";
# Hashes storage time (3 months)
expire = 90d;
# Synchronize updates to the storage each minute
sync = 1min;
}
Access control setup
Rspamd does not allow to modify data in the repository by default. It is required to specify a list of trusted IP-addresses and/or networks to make learning possible. Practically, it is better to write from the local address only (127.0.0.1) since fuzzy storage uses UDP that is not protected from source IP forgery.
worker "fuzzy" {
# Same options as before ...
allow_update = ["127.0.0.1"];
# or 10.0.0.0/8, for internal network
}
Transport encryption might also be used for access control purposes.
Transport encryption
Fuzzy hashes protocol allows to enable optional (opportunistic) or mandatory encryption based on public-key cryptography. Encryption architecture uses cryptobox construction: https://nacl.cr.yp.to/box.html and it is similar to the algorithm for end-to-end encryption used in DNSCurve protocol: https://dnscurve.org/.
To configure transport encryption, it is necessary to create a keypair for storage server using the command rspamadm keypair -u:
keypair {
pubkey = "og3snn8s37znxz53mr5yyyzktt3d5uczxecsp3kkrs495p4iaxzy";
privkey = "o6wnij9r4wegqjnd46dyifwgf5gwuqguqxzntseectroq7b3gwty";
id = "f5yior1ag3csbzjiuuynff9tczknoj9s9b454kuonqknthrdbwbqj63h3g9dht97fhp4a5jgof1eiifshcsnnrbj73ak8hkq6sbrhed";
encoding = "base32";
algorithm = "curve25519";
type = "kex";
}
This command creates a unique keypair, where public key should be copied manually to the customer’s host (e.g. via ssh) or published in any way to guarantee the reliability (e.g. certified digital signature or HTTPS-site hosting).
Each storage can use any number of keys simultaneously:
worker "fuzzy" {
# Same options as before ...
keypair {
pubkey = ...
privkey = ...
}
keypair {
pubkey = ...
privkey = ...
}
keypair {
pubkey = ...
privkey = ...
}
}
This feature is useful for creating restricted storages where access is allowed merely to those customers who knows about one of the public keys of storage:
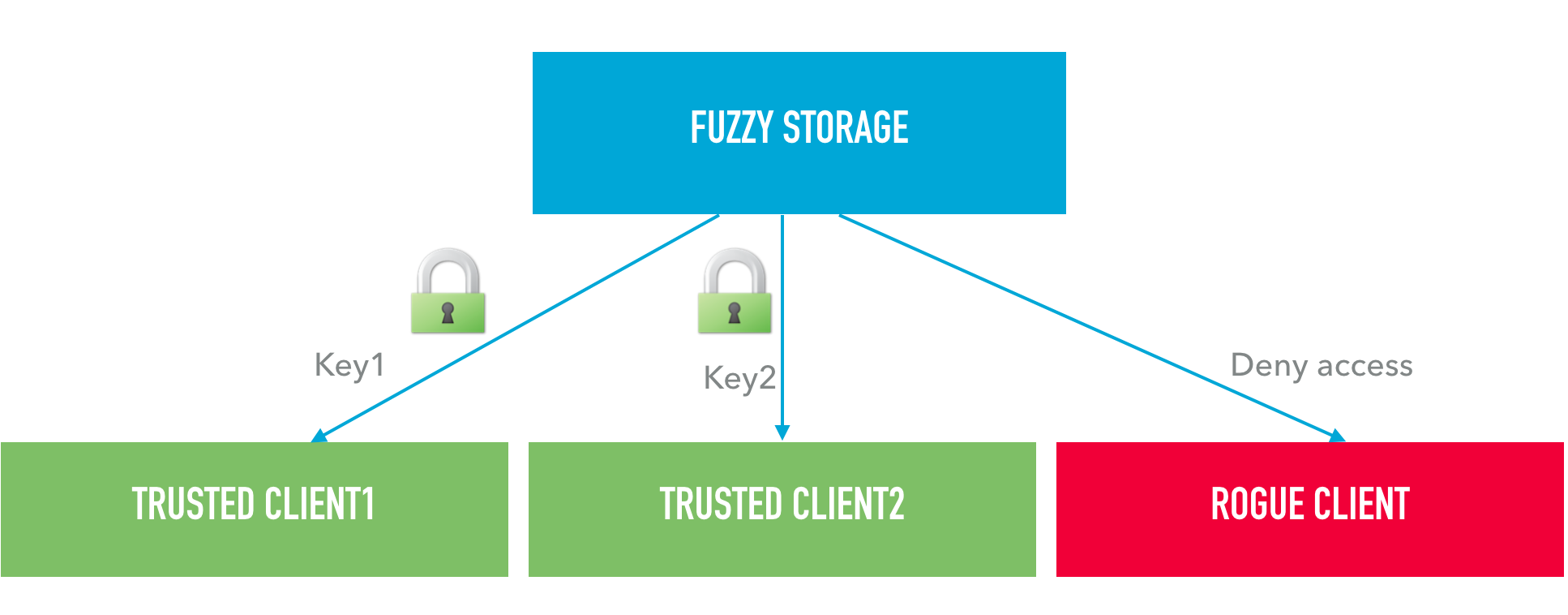
To enable such a mandatory encryption mode you should use encrypted_only option:
worker "fuzzy" {
# Same options as before ...
encrypted_only = true;
keypair {
...
}
...
}
Clients who do not have a valid public key are not able to access the storage in this mode.
Storage testing
To test the storage you can use rspamadm control fuzzystat command:
Statistics for storage 73ee122ac2cfe0c4f12
invalid_requests: 6.69M
fuzzy_expired: 35.57k
fuzzy_found: (v0.6: 0), (v0.8: 0), (v0.9: 0), (v1.0+: 20.10M)
fuzzy_stored: 425.46k
fuzzy_shingles: (v0.6: 0), (v0.8: 41.78k), (v0.9: 23.60M), (v1.0+: 380.87M)
fuzzy_checked: (v0.6: 0), (v0.8: 95.29k), (v0.9: 55.47M), (v1.0+: 1.01G)
Keys statistics:
Key id: icy63itbhhni8
Checked: 1.00G
Matched: 18.29M
Errors: 0
Added: 1.81M
Deleted: 0
IPs stat:
x.x.x.x
Checked: 131.23M
Matched: 1.85M
Errors: 0
Added: 0
Deleted: 0
x.x.x.x
Checked: 119.86M
...
Primarily, a general storage statistics is shown, namely the number of stored and obsolete hashes, as well as the requests distribution for versions of the client Protocol:
v0.6- requests from rspamd 0.6 - 0.8 (older versions, compatibility is limited)v0.8- requests from rspamd 0.8 - 0.9 (partially compatible)v0.9- unencrypted requests from rspamd 0.9+ (fully compatible)v1.1- encrypted requests from rspamd 1.1+ (fully compatible)
And then detailed statistics is displayed for each of the keys configured in the storage and for the latest requested client IP-addresses. In conclusion, we see the overall statistics on IP-addresses.
To change the output from this command, you can use the following options:
-n: display raw numbers without reduction--short: do not display detailed statistics on the keys and IP-addresses--no-keys: do not show statistics on keys--no-ips: do not show statistics on IP-addresses--sort: sort:checked: by the number of trusted hashes (default)matched: by the number of found hasheserrors: by the number of failed requestsip: by IP-address lexicographically
e.g.
rspamadm control fuzzystat -n
Step 3: Configuring fuzzy_check plugin
fuzzy_check plugin is used by scanner processes for querying a storage and by controller processes for learning fuzzy hashes.
Plugin functions:
- Email processing and hashes creating from the email parts and attachements
- Querying and learning the storage
- Transport Encryption
Learning is performing by rspamc fuzzy_add command:
$ rspamc -f 1 -w 10 fuzzy_add <message|directory|stdin>
Where -w parameter is for setting the hash weight discussed above whilst -f parameter specifies the flag number.
Flags allow to store hashes of different origin in storage. For example, the hash of spam traps, hashes of user complaints and hashes of emails that come from a “white” list. Each flag may be associated with its own symbol and have a weight while checking emails:
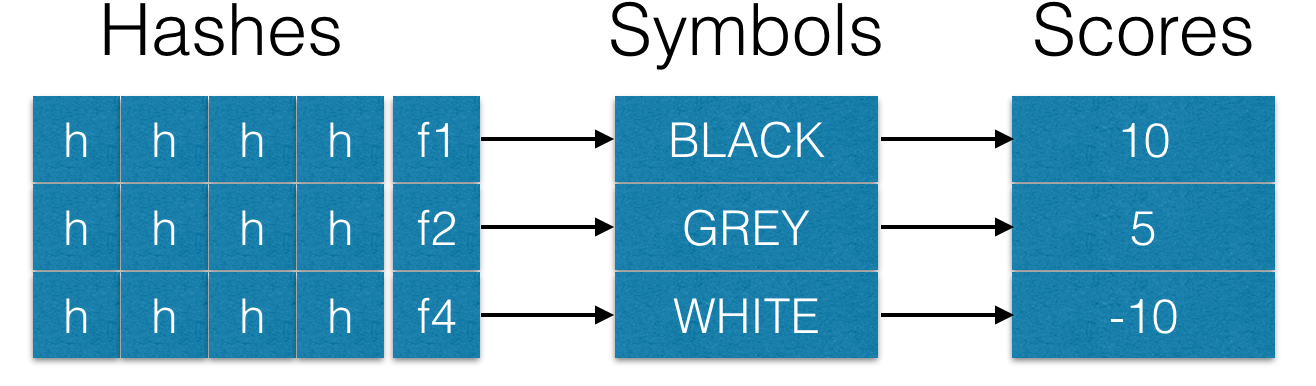
Symbol name could also be used instead of a numeric flag during learning, e.g.:
$ rspamc -S FUZZY_DENIED -w 10 fuzzy_add <message|directory|stdin>
To match symbols with the corresponding flags you can use the rule section.
local.d/fuzzy_check.conf example:
rule "local" {
# Fuzzy storage server list
servers = "localhost:11335";
# Default symbol for unknown flags
symbol = "LOCAL_FUZZY_UNKNOWN";
# Additional mime types to store/check
mime_types = ["*"];
# Hash weight threshold for all maps
max_score = 20.0;
# Whether we can learn this storage
read_only = no;
# Ignore unknown flags
skip_unknown = yes;
# Hash generation algorithm
algorithm = "mumhash";
# Use direct hash for short texts
short_text_direct_hash = true;
# Map flags to symbols
fuzzy_map = {
LOCAL_FUZZY_DENIED {
# Local threshold
max_score = 20.0;
# Flag to match
flag = 11;
}
LOCAL_FUZZY_PROB {
max_score = 10.0;
flag = 12;
}
LOCAL_FUZZY_WHITE {
max_score = 2.0;
flag = 13;
}
}
}
local.d/fuzzy_group.conf example:
max_score = 12.0;
symbols = {
"LOCAL_FUZZY_UNKNOWN" {
weight = 5.0;
description = "Generic fuzzy hash match";
}
"LOCAL_FUZZY_DENIED" {
weight = 12.0;
description = "Denied fuzzy hash";
}
"LOCAL_FUZZY_PROB" {
weight = 5.0;
description = "Probable fuzzy hash";
}
"LOCAL_FUZZY_WHITE" {
weight = -2.1;
description = "Whitelisted fuzzy hash";
}
}
Let’s discuss some useful options that could be set in the module.
Firstly, max_score specifies the threshold for a hash weight:
Another useful option is mime_types that specifies what attachments types are checked (or learned) using this fuzzy rule. This parameter contains a list of valid types in format: ["type/subtype", "*/subtype", "type/*", "*"], where * matches any valid type. In practice, it is quite useful to save the hashes for all application/* attachments. Texts and embedded images are implicitly checked by fuzzy_check plugin, so there is no need to add image/* in the list of scanned attachments. Please note that attachments and images are searched for the exact match whilst texts are matched using the approximate algorithm (shingles).
read_only is quite an important option required for storage learning. It is set to read_only=true by default, restricting thus a storage’s learning:
read_only = true; # disallow learning
read_only = false; # allow learning
Encryption_key parameter specifies the public key of a storage and enables encryption for all requests.
Algorithm parameter specifies the algorithm for generating hashes from text parts of emails (for attachments and images blake2b is always used).
Initially, rspamd used merely siphash algorithm. However, it has some performance issues, especially on obsolete hardware (CPU until Intel Haswell). Therefore it could be better to use another algorithms when creating a new storage:
xxhashmumhashfasthash
For the vast majority of configurations we recommend to use mumhash or fasthash that shows an excellent performance on a wide variety of platforms. You can also evaluate the performance of different algorithms by compiling the tests set from rspamd sources:
$ make rspamd-test
and run the test suite of different variants of hash algorithms on a specific platform:
test/rspamd-test -p /rspamd/shingles
Important note: it is not possible to change the parameter without losing all data in the storage, as only one algorithm can be used simultaneously for each storage. Conversion of one type of hash to another is impossible by design as a hash function cannot be reversed.
Condition scripts for the learning
As the fuzzy_check plugin is responsible for learning, we create the script within its configuration. This script checks if a email is suitable for learning. Script should return a Lua function with exactly one argument of rspamd_task type. This function should return either a boolean value: true - learn, false - skip learning, or a pair of a boolean value and numeric value - new flag value in case it is required to modify the hash flag. Parameter learn_condition is used to setup learn script. The most convenient way to set the script is to write it as a multiline string supported by UCL:
# Fuzzy check plugin configuration snippet
learn_condition = <<EOD
return function(task)
return true -- Always learn
end
EOD;
Here are some practical examples of useful scripts. For instance, if we want to restrict learning for messages that come from certain domains:
return function(task)
local skip_domains = {
'example.com',
'google.com',
}
local from = task:get_from()
if from and from[1] and from[1]['addr'] then
for i,d in ipairs(skip_domains) do
if string.find(from[1]['addr'], d) then
return false
end
end
end
end
Also, it is useful to split hashes to various flags in accordance with their source. For example, such sources may be encoded in the X-Source title. For instance, we have the following match between flags and sources:
honeypot- “black” list: 1users_unfiltered- “gray” list: 2users_filtered- “black” list: 1FP- “white” list: 3
Then the script that provides this logic may be as following:
return function(task)
local skip_headers = {
['X-Source'] = function(hdr)
local sources = {
honeypot = 1,
users_unfiltered = 2,
users_filtered = 1,
FP = 3
}
local fl = sources[hdr]
if fl then return true,fl end -- Return true + new flag
return false
end
}
for h,f in pairs(skip_headers) do
local hdr = task:get_header(h) -- Check for interesting header
if h then
return f(hdr) -- Call its handler and return result
end
end
return false -- Do not learn if specified header is missing
end
Step 4: Hashes replication
It is often desired to have a local copy of the remote storage. Rspamd supports replication for this purposes that is implemented in the hashes storage since version 1.3:
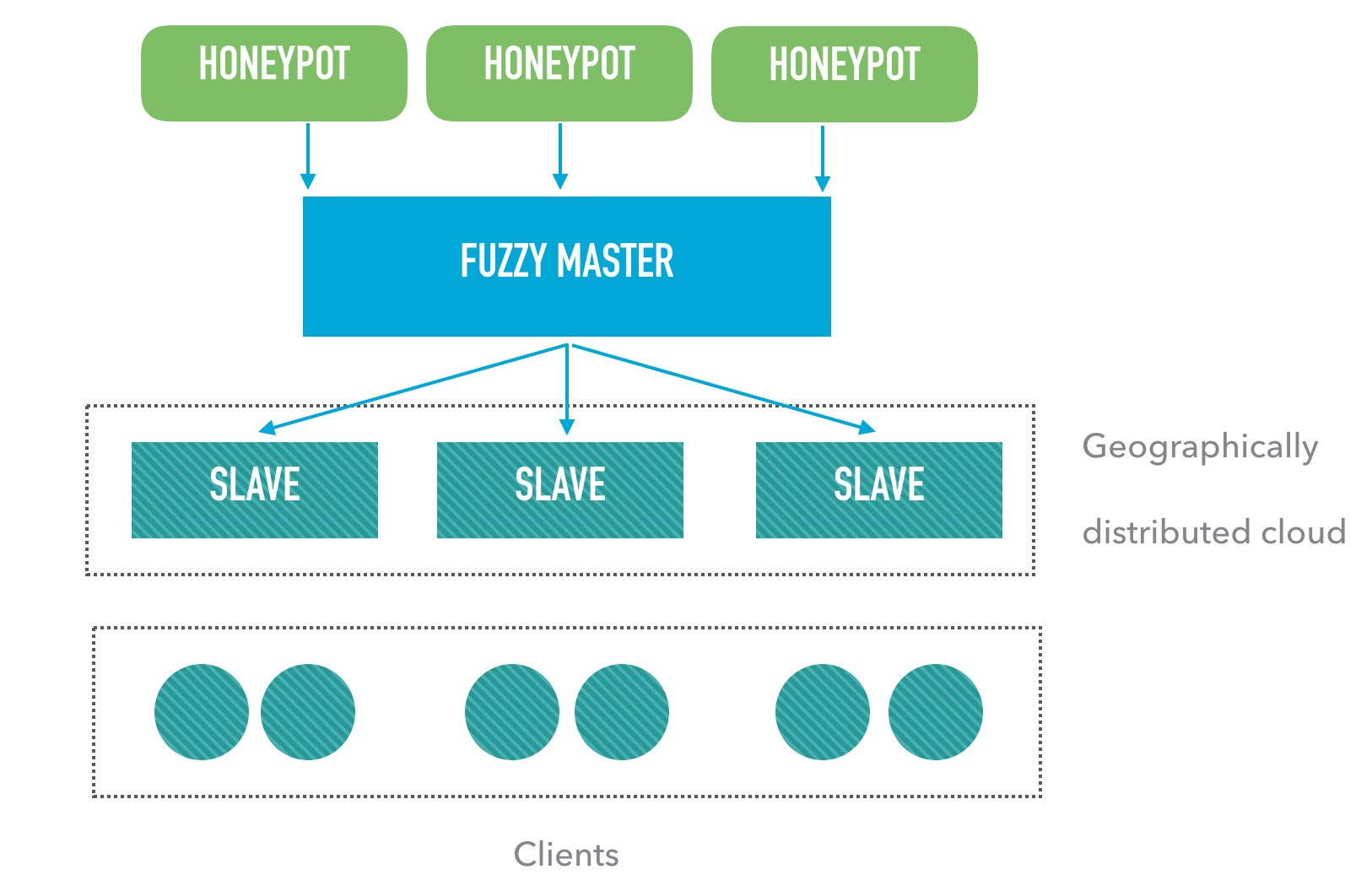
The hashes transfer is initiated by the replication master. It sends hash update commands, such as adding, modifying or deleting, to all specified slaves. Hence, the slaves should be able to accept such a connection from the master - it should be considered while configuring a firewall.
A slave normally listens on the same port 11335 (by default) over TCP to accept a connection. The master and the slave synchronization are occurred via the HTTP protocol with HTTPCrypt transport encryption. The slave checks the update version to prevent repeated or invalid updates. If the master’s version is less or equal to the local one, then the update is rejected. But if the master is ahead of the slave for more than one version, the following message will appear in the log file of the slave:
rspamd_fuzzy_mirror_process_update: remote revision: XX is newer more than 1 revision than ours: YY, cold sync is recommended
In this case we recommend to re-create the database through a “cold” synchronization.
The “cold” synchronization
This procedure is used to initialize a new slave or to recover a slave after the communications with the master is interrupted.
To synchronize the master host you need to stop rspamd service and create a dump of hash database. In theory, you can skip this step, however, if a version of the master increases by more than one while database cloning, it will be required to repeat the procedure:
sqlite3 /var/lib/rspamd/fuzzy.db ".backup fuzzy.sql"
Afterwards, copy the output file fuzzy.sql to all the slaves (it can be done without stopping rspamd service on the slaves):
sqlite3 /var/lib/rspamd/fuzzy.db ".restore fuzzy.sql"
After all, you can run rspamd on the slaves and then switch on the master.
Replication setup
You can set the replication in the hashes storage configuration file, namely worker-fuzzy.inc. Master replication is configured as follows:
# Fuzzy storage worker configuration snippet
# Local keypair (rspamadm keypair -u)
sync_keypair {
pubkey = "xxx";
privkey = "ppp";
encoding = "base32";
algorithm = "curve25519";
type = "kex";
}
# Remote slave
slave {
name = "slave1";
hosts = "slave1.example.com";
key = "yyy";
}
slave {
name = "slave2";
hosts = "slave2.example.com";
key = "zzz";
}
Let’s focus on configuring the encryption keys. Typically, rspamd does not require dedicated setup for a client’s keypair as such a keypair is generated automatically. However, in replication case, the master acts as the client, so you can set a specific (public) key on the slaves for better access control. The slaves will allow updates merely for hosts that are using this key. It is also possible to set allowed IP-addresses of the master, but public key based protection seems to be more reliable. As an option, you can combine these methods.
The slave setup looks similar:
# Fuzzy storage worker configuration snippet
# We assume it is slave1 with pubkey 'yyy'
sync_keypair {
pubkey = "yyy";
privkey = "PPP";
encoding = "base32";
algorithm = "curve25519";
type = "kex";
}
# Allow update from these hosts only
masters = "master.example.com";
# Also limit updates to this specific public key
master_key = "xxx";
It is possible to set a flag translation from the master to the slave in order to avoid conflicts with the local hashes. For example, if we want to translate the flags 1, 2 and 3 to the flags 10, 20 and 30 accordingly, we can use the following configuration:
# Fuzzy storage worker configuration snippet
master_flags {
"1" = 10;
"2" = 20;
"3" = 30;
};