Rspamd statistic settings
Introduction
Statistics is used by Rspamd to define the class of message: either spam or ham. The overall algorithm is based on Bayesian theorem
that defines probabilities combination. In general, it defines the probability of that a message belongs to the specified class (namely, spam or ham)
base on the following factors:
- the probability of a specific token to be spam or ham (which means efficiently count of a token’s occurrences in spam and ham messages)
- the probability of a specific token to appear in a message (which efficiently means frequency of a token divided by a number of tokens in a message)
Statistics Architecture
However, Rspamd uses more advanced techniques to combine probabilities, such as sparsed bigramms (OSB) and inverse chi-square distribution.
The key idea of OSB algorithm is to use not merely single words as tokens but combinations of words weighted by theirs positions.
This schema is displayed in the following picture:
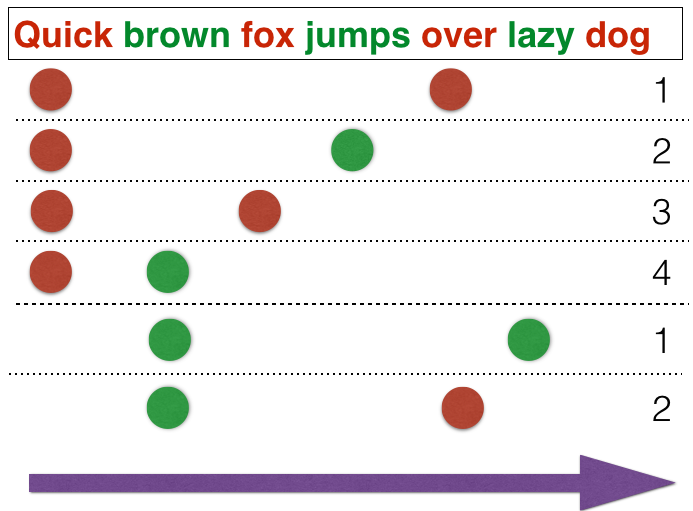
The main disadvantage is the amount of tokens which is multiplied by size of window. In Rspamd, we use a window of 5 tokens that means that the number of tokens is around 5 times larger than the amount of words.
Statistical tokens are stored in statfiles which, in turn, are mapped to specific backends. This architecture is displayed in the following image:
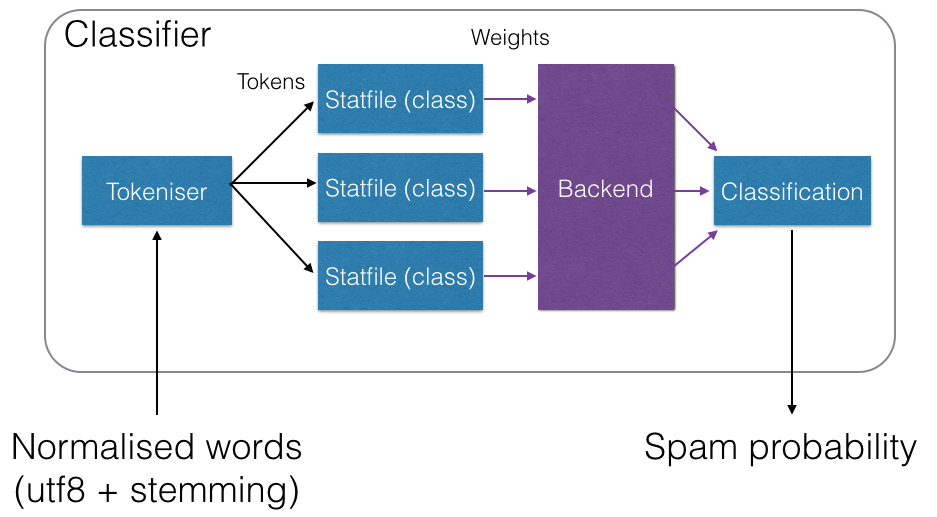
Statistics Configuration
Starting from Rspamd 2.0, we propose to use redis as backed and osb as tokenizer and that are the default settings. Here are the default settings placed in $CONFDIR/statistic.conf
classifier "bayes" {
tokenizer {
name = "osb";
}
cache {
}
new_schema = true; # Always use new schema
store_tokens = false; # Redefine if storing of tokens is desired
signatures = false; # Store learn signatures
#per_user = true; # Enable per user classifier
min_tokens = 11;
backend = "redis";
min_learns = 200;
statfile {
symbol = "BAYES_HAM";
spam = false;
}
statfile {
symbol = "BAYES_SPAM";
spam = true;
}
learn_condition = 'return require("lua_bayes_learn").can_learn';
# Autolearn sample
# autolearn {
# spam_threshold = 6.0; # When to learn spam (score >= threshold)
# ham_threshold = -0.5; # When to learn ham (score <= threshold)
# check_balance = true; # Check spam and ham balance
# min_balance = 0.9; # Keep diff for spam/ham learns for at least this value
#}
.include(try=true; priority=1) "$LOCAL_CONFDIR/local.d/classifier-bayes.conf"
.include(try=true; priority=10) "$LOCAL_CONFDIR/override.d/classifier-bayes.conf"
}
.include(try=true; priority=1) "$LOCAL_CONFDIR/local.d/statistic.conf"
.include(try=true; priority=10) "$LOCAL_CONFDIR/override.d/statistic.conf"
It is also possible to organize per-user statistics, however, you should ensure that Rspamd is called at the
finally delivery stage (e.g. LDA mode) to avoid multi-recipients messages. In case of a multi-recipient message, Rspamd would just use the
first recipient for user-based statistics which might be inappropriate for your configuration (Rspamd prefers SMTP recipients over MIME ones and prioritize
the special LDA header called Delivered-To that can be appended by -d options for rspamc). To enable per-user statistics, just add users_enabled = true property
to the classifier configuration.
Classifier and headers
The classifer will only learn headers that are defined in classify_headers in the options.inc file. It is therefore not necessary to remove any headers added (such as X-Spam or others) before learning, as these headers will not be used for classification. Rspamd also uses Subject that is tokenized according to the rules above and several meta-tokens, such as size or number of attachments that are extracted from the messages.
Redis statistics
Supported parameters for the redis backend are:
tokenizer: leave it as shown for now. Currently only osb is supportedbackend: set it to redisservers: IP or hostname with port for the redis server. Use an IP for the loopback interface, if you have defined localhost in /etc/hosts for both IPv4 and IPv6, or your redis server will not be found!write_servers(optional): If needed, define dedicated servers for learningpassword(optional): Password for the redis serverdb(optional): Database to use (though it is recommended to use dedicated redis instances and not databases in redis)min_tokens: minimum number of words required for statistics processingmin_learns(optional): minimum learn count for both spam and ham classes to perform classificationautolearn(optional): see below for detailsper_user(optional): enable per users statistics. See abovestatfile: Define keys for spam and ham mails.learn_condition(optional): Lua function for autolearning as described below.
You are also recommended to use bayes_expiry module to maintain your statistics database.
Autolearning
From version 1.1, Rspamd supports autolearning for statfiles. Autolearning is applied after all rules are processed (including statistics) if and only if the same symbol has not been inserted. E.g. a message won’t be learned as spam if BAYES_SPAM is already in the results of checking.
There are 3 possibilities to specify autolearning:
autolearn = true: autolearning is performing as spam if a message hasrejectaction and as ham if a message has negative scoreautolearn = [-5, 5]: autolearn as ham if score is less-5and as spam if score is more than5autolearn = "return function(task) ... end": use the following Lua function to detect if autolearn is needed (function should return ‘ham’ if learn as ham is needed and string ‘spam’ if learn as spam is needed, if no learn is needed then a function can return anything includingnil)
Redis backend is highly recommended for autolearning purposes since it’s the only backend with high concurrency level when multiple writers are properly synchronized.